基于 Scal 语言的 Spark 数据分析案例:NBA 球员数据处理与可视化
作者:夏嘉儿,厦门大学信息科学与技术学院人工智能系2021级研究生
指导老师:林子宇博士,厦门大学数据库实验室副教授
相关教材:《Spark编程基础(Scala版)》林子宇、郑海山、赖永宣编著
【查看基于Scala语言的Spark数据分析案例集锦】
本案例对NBA球员数据进行分析,使用Scala作为编程语言,使用Hadoop存储数据,使用Spark对数据进行处理分析,并将结果进行可视化。
1.实验环境
1)Linux:Ubuntu 18.04.6 LTS
2)Hadoop:3.1.3
3)Spark:3.2.0
4)Python 3.8.10
5)Scala:2.12.15
6)IntelliJ IDEA:2022.1
7)SBT:1.6.2
二、数据处理 (1)数据集描述
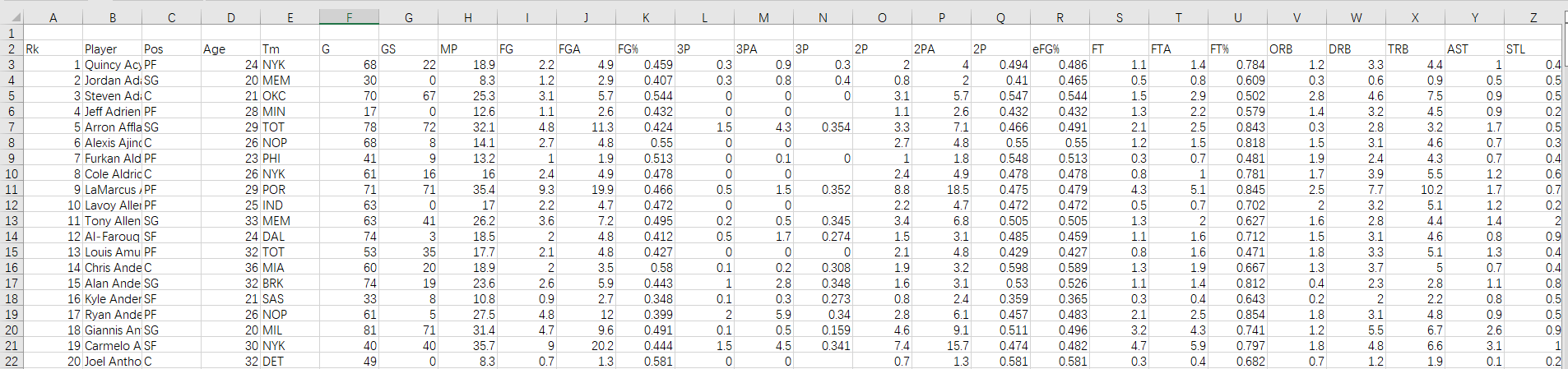
本实验所用的数据集来自NBA官网公布的数据库(),该数据集爬取了1970年至2015年46年的球员比赛数据,数据集可以在百度网盘下载(提取码:ziyu),数据内容及字段说明如下:
rk:每个文件中的行号
玩家:玩家姓名
位置:球员位置
年龄:球员年龄
Tm:团队
G:出场次数(场次)
GS:比赛开始
MP:上场时间
FG: 射门得分
FGA:射门得分
FG%:投篮命中率
3P:三分球
3PA:三分球出手次数
3P%:三分球命中率
2P:2分投篮命中率
2PA: 两分球
2P%:两分球命中率
eFG%:有效投篮命中率(不包括罚球)
FT:罚球命中
FTA:罚球次数
FT%:罚球命中率
ORB:进攻篮板
DRB:进攻篮板
TRB:总篮板
AST:助攻
STL:偷取时间
BLK: 区块时间
TOV:营业额
PF:个人犯规
PTS:总分(点数)
(2)数据集存储(HDFS)
获取原始数据后,首先通过Hadoop中的HDFS组件将数据集存储到分布式文件系统HDFS中,具体步骤如下:
①在终端启动HDFS:/usr/local/hadoop/sbin/start-dfs.sh
②在HDFS中创建存储路径:hdfs dfs -mkdir -p /xje/hadoop/nba
③上传文件到HDFS:hdfs dfs -put basketball /xje/hadoop/nba
注:本次实验使用的数据集是一个文件夹,里面有46个csv文件,所以直接上传basketball文件夹。使用单文件数据集时,直接上传csv文件即可。
(3)数据集预处理
在进行数据分析之前,首先要对数据进行预处理,删除无效数据(例如空白行),并对数据进行规范化,以便后续的数据处理能够更加顺利地进行。
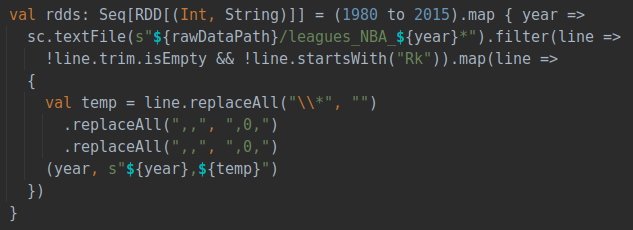
为此,直接运行 Player_Stats_Preprocess.scala 文件,但请确保代码中的 rawDataPath 是正确的数据集路径。
清洗完数据集之后,由于爬取的数据集是按照年份单独爬取的,所以需要将46个不同年份的数据进行整合。直接运行ZscoreCalculator.scala文件,代码会读取各个年份的csv文件并进行合并,并对数据进行预处理。同时根据球员每一年的数据计算出球员在每一年的zScore,作为球员表现的评价指标(实验过程中会详细描述),最后整合保存为一个包含每一年数据的文件。
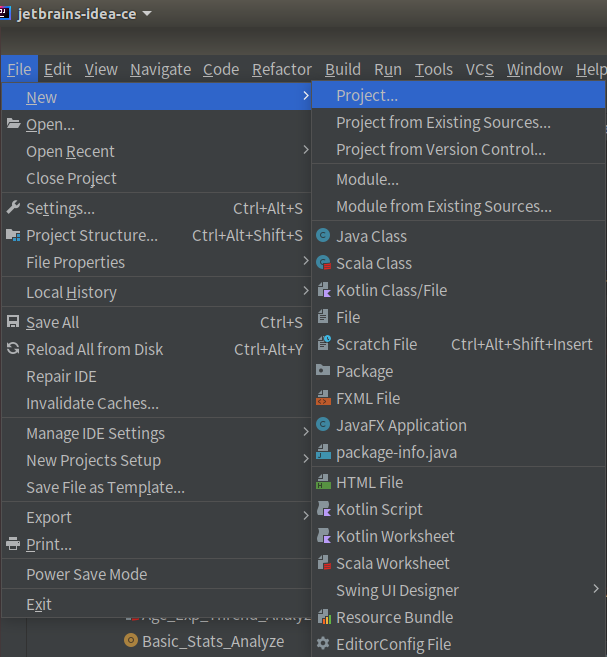
3.配置项目 (1)创建IDEA项目
①首先,创建一个新项目,点击文件->新建->项目
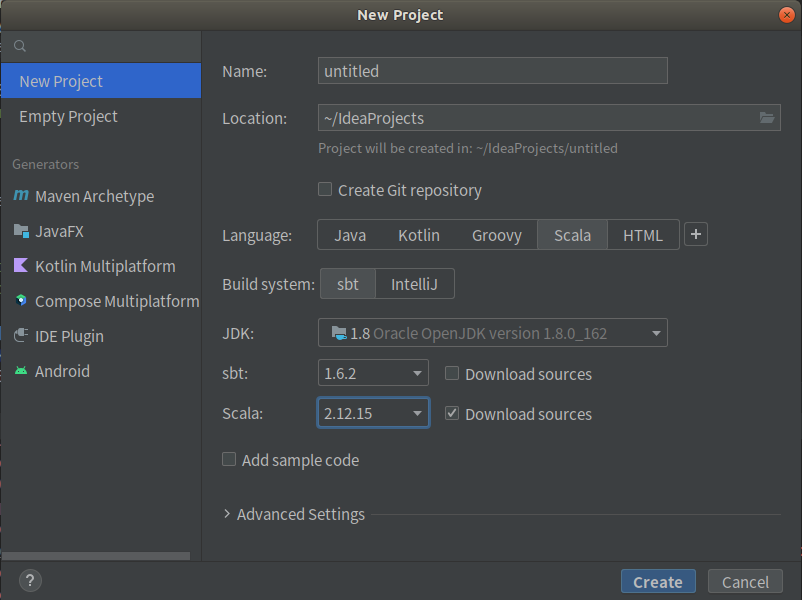
②基于SBT搭建Scala项目,选择Scala版本2.12.15
(2)添加jar包
①打开文件->项目结构
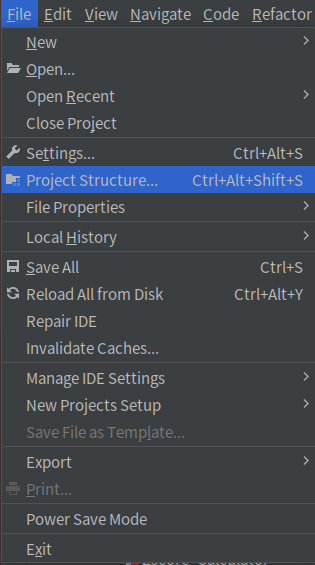
②添加Spark罐
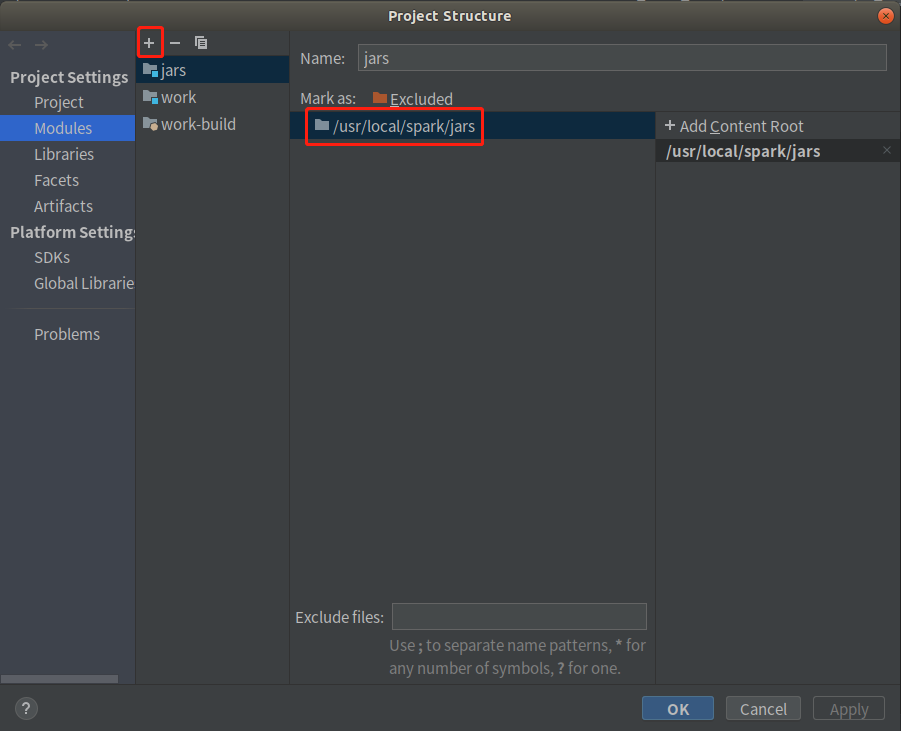
(3)本地单行操作配置文件
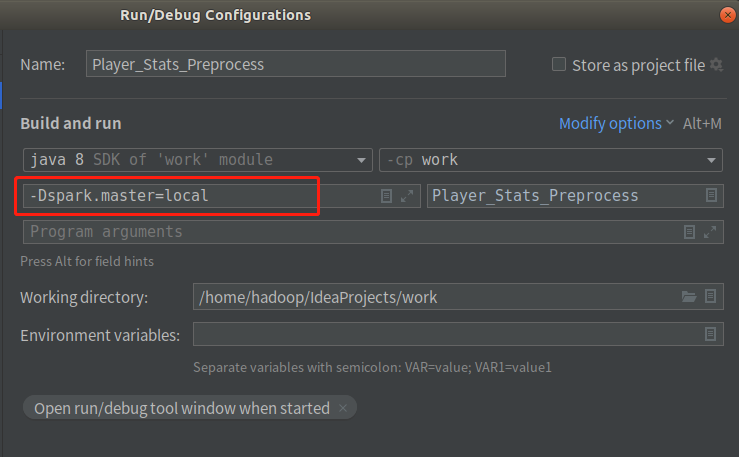
①选择右上角的Edit Configuration
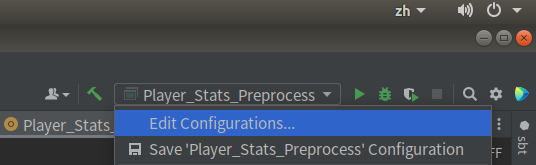
②在Modify选项中选择AddVM选项
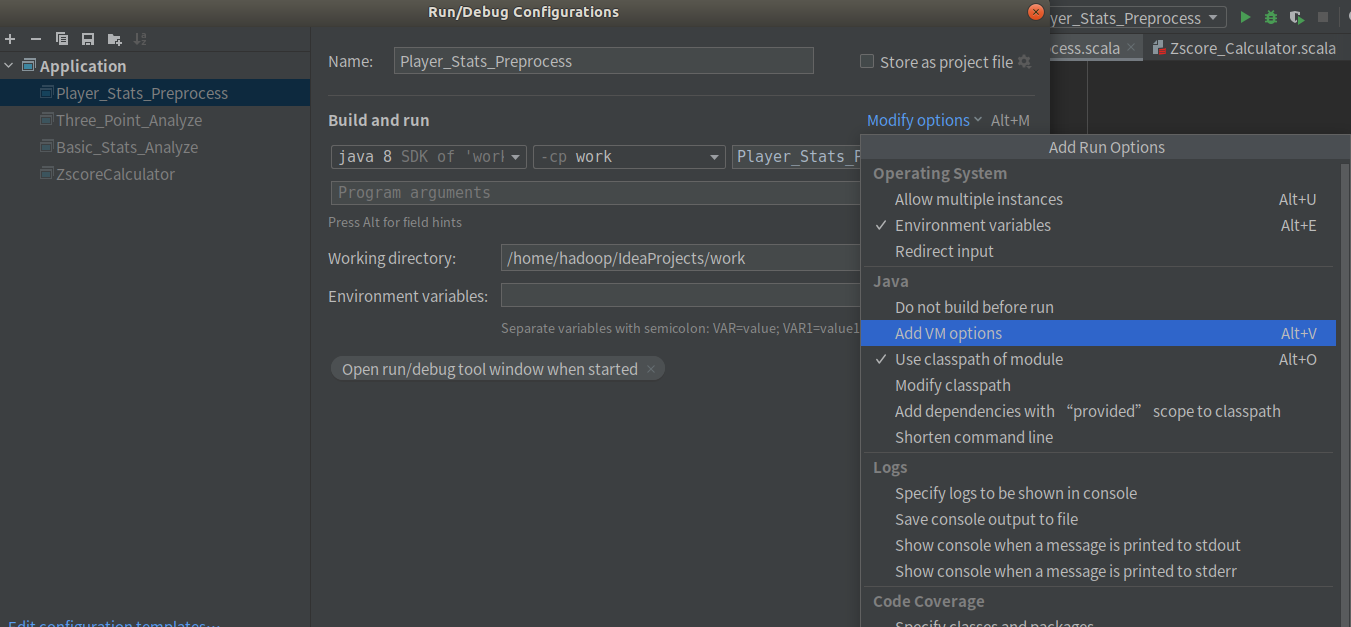
③在VM选项中输入-Dspark.master=local,指示该程序在本地单线程中运行。
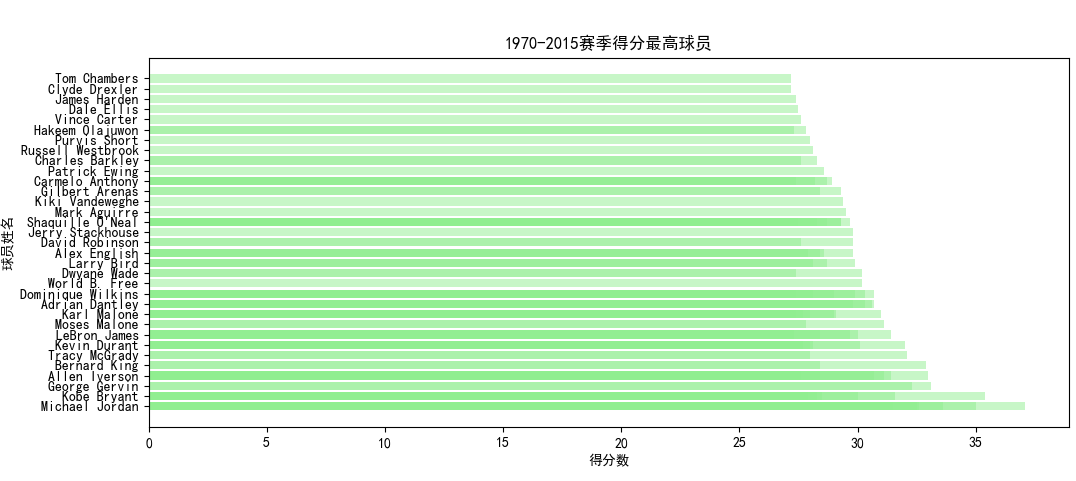
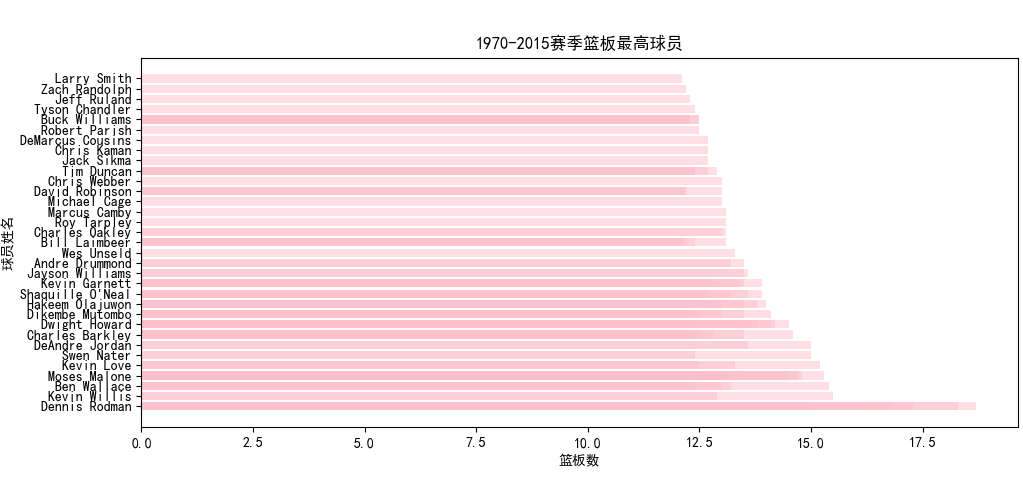
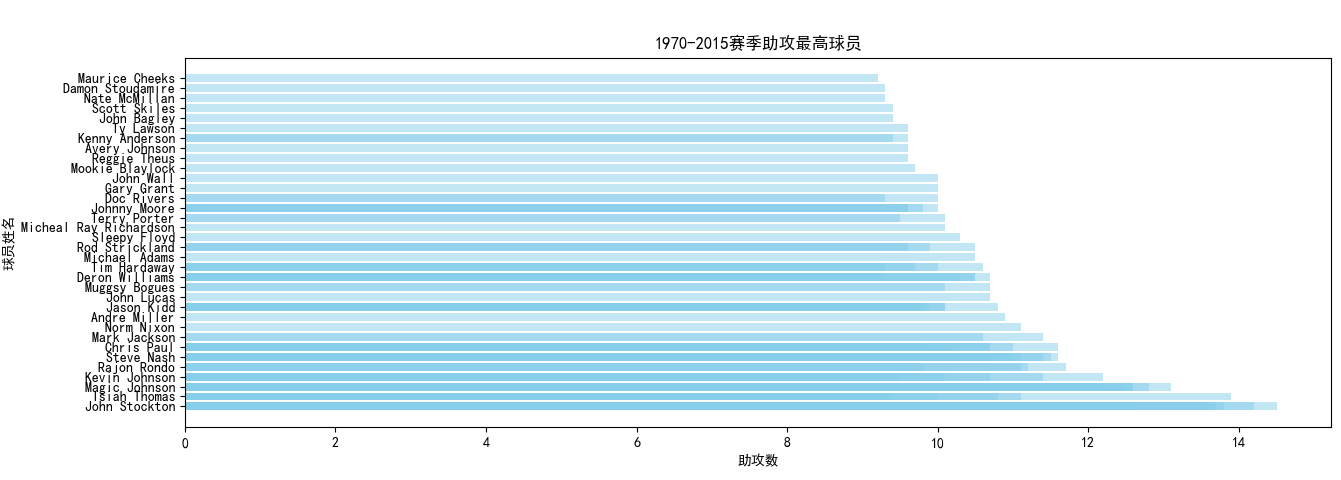
四、数据分析 (1)筛选1970年至2015年100个主要数据排名
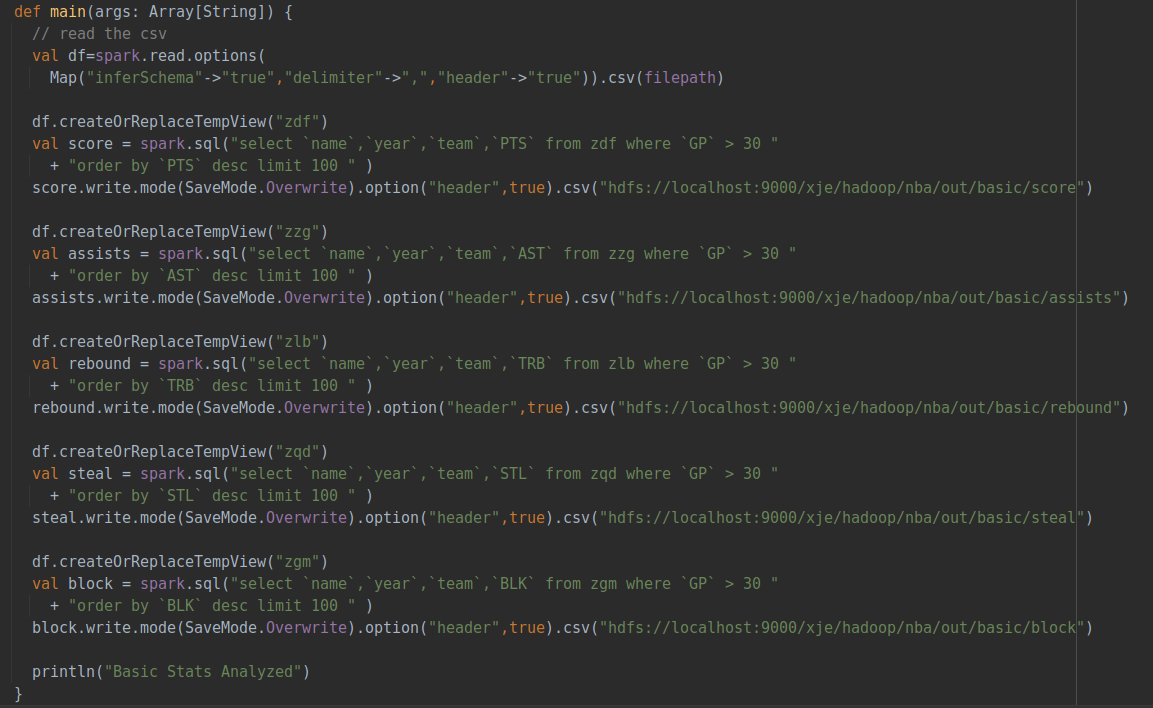
使用spark.sql语句从数据库中选取球员姓名、年份、球队以及需要分析的数据(包括得分、篮板、助攻、盖帽、抢断)。同时按GP即出场次数进行筛选,出场次数必须大于30,防止统计出场次数少的不可靠数据。
将数据按照得分或者篮板等进行降序排列,然后输出写入csv并存储在HDFS中。
(2)1970年至2015年三分球投篮数据年度变化分析
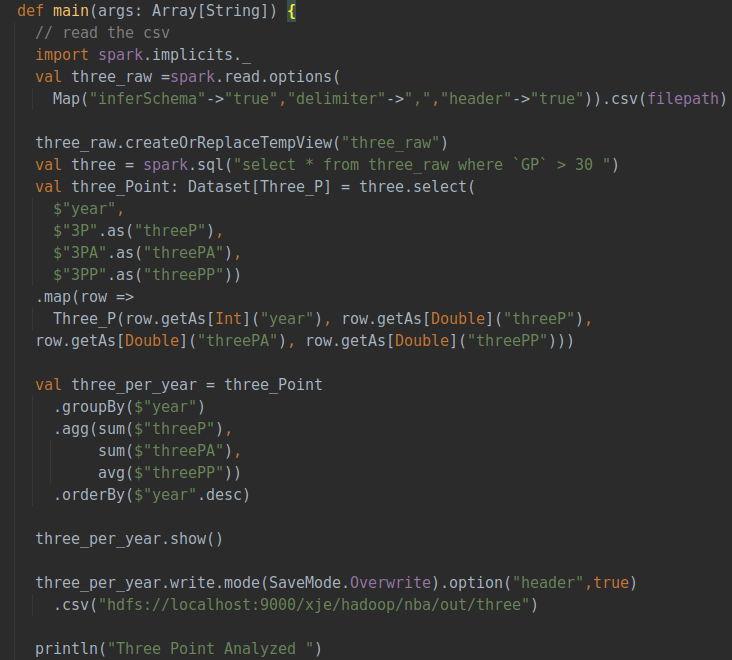
本节分析随着赛季的进行,比赛中三分球出手占比的变化,主要分析三分球出手次数、命中次数以及命中率。分析之前先声明一个三分球类,用于接受需要的三分球相关字段数据,然后具体分析流程如下:
① 读取csv数据集,并按出现次数筛选数据
②选择所需字段并创建数据集
③ 按年份分组,汇总每年的三点数据
④保存处理后的数据
具体代码如下:
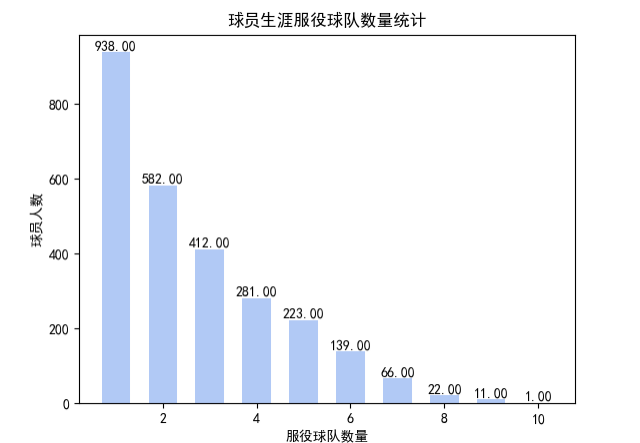
(3)所有球员效力球队数统计
本节分析联盟中不同球员换队的情况,即统计每个球员所在球队类型数,具体流程如下:
①读取csv数据集
②选择姓名和团队字段,创建Dataset类
③ 将队员按照姓名分组,统计各队员队伍中出现的类型数量
④ 统计后再对每个玩家所属球队数进行汇总统计
⑤保存处理后的数据
具体代码如下:
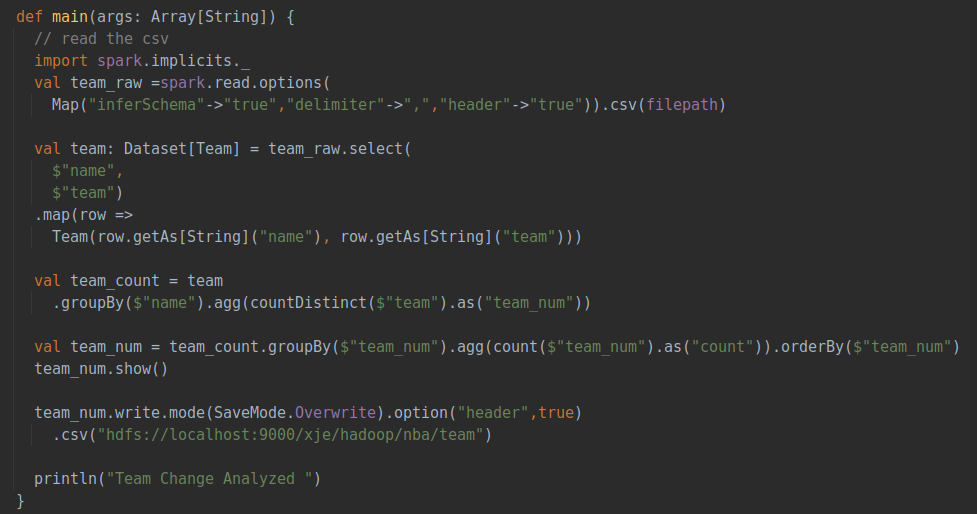
Dataset类的GroupBy、agg操作主要用来对数据进行分组、聚类,最后统计出队伍变更总数并按照队伍数量排序输出,运行后的输出结果如下:
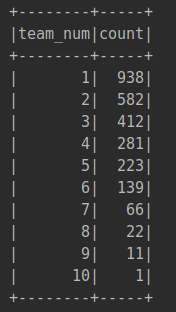
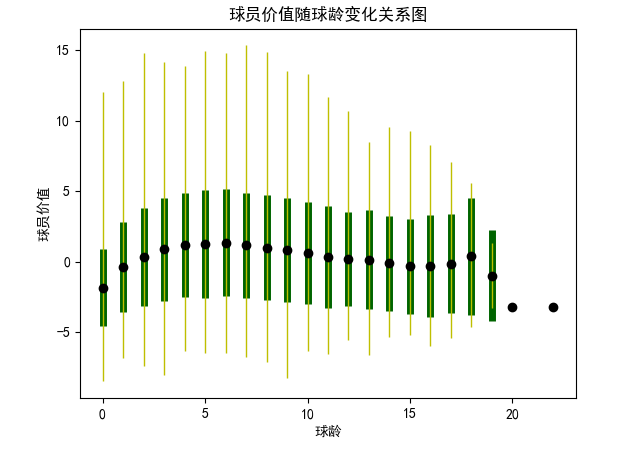
(4)分析年龄、比赛经验与球员价值的关系
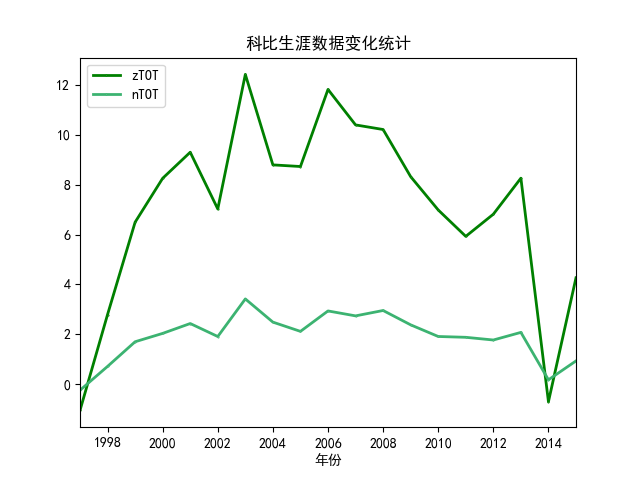
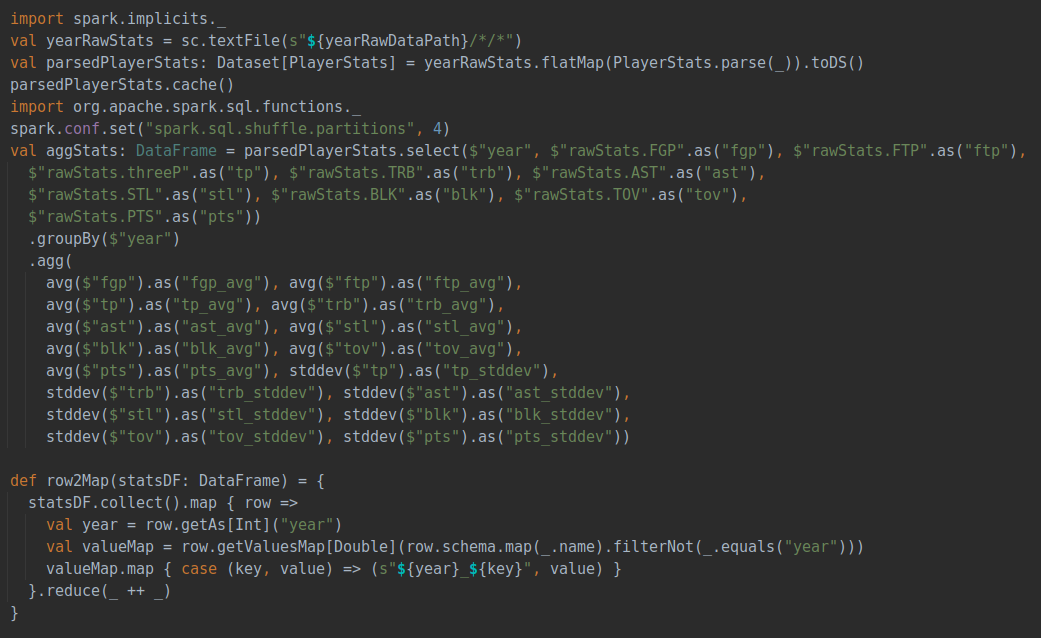
这部分分析了球员的价值和年龄、球技之间的关系。首先我们需要对球员的价值有一个量化的评估,这部分就是数据预处理中提到的zScore的计算。zScore是通过三分球命中率、总篮板数、总助攻数、总抢断数、总盖帽数、总失误数、总得分七项指标综合评估出来的。nzScore则是在这个基础上加上投篮命中率、罚球命中率两项指标,一共九项指标评估出来的。计算代码如下:
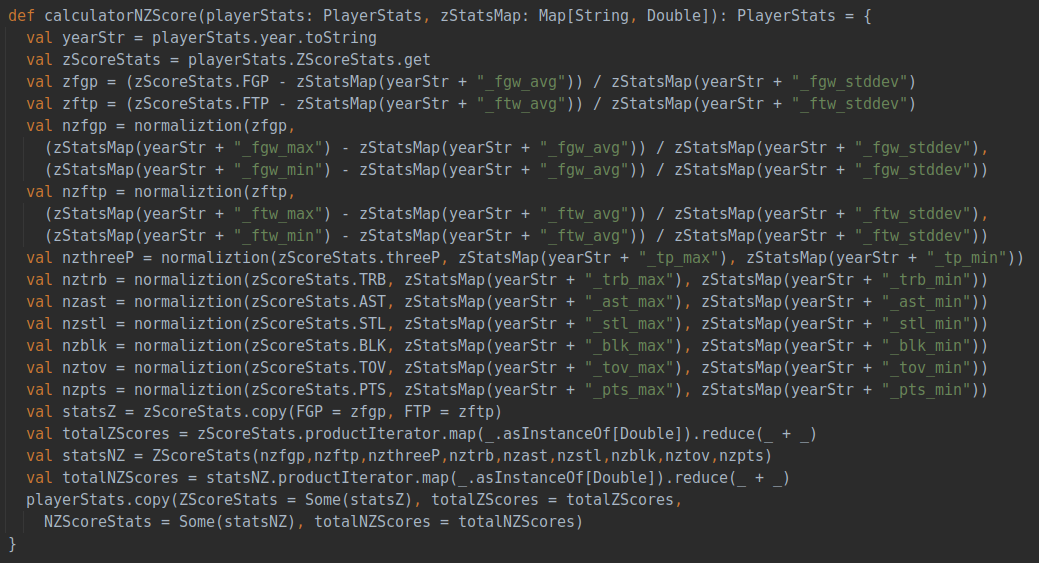
所有指标都会用全年所有数据计算出来的均值和标准差进行标准化,以保证每个数据都在同一尺度上,保证每年的评价指标相对一致。得到每年每个球员的评价分数后,随着年份的变化对球员的身价变化进行评估和汇总,得到球员身价随着年龄或上场时间变化的变化关系。具体代码如下:
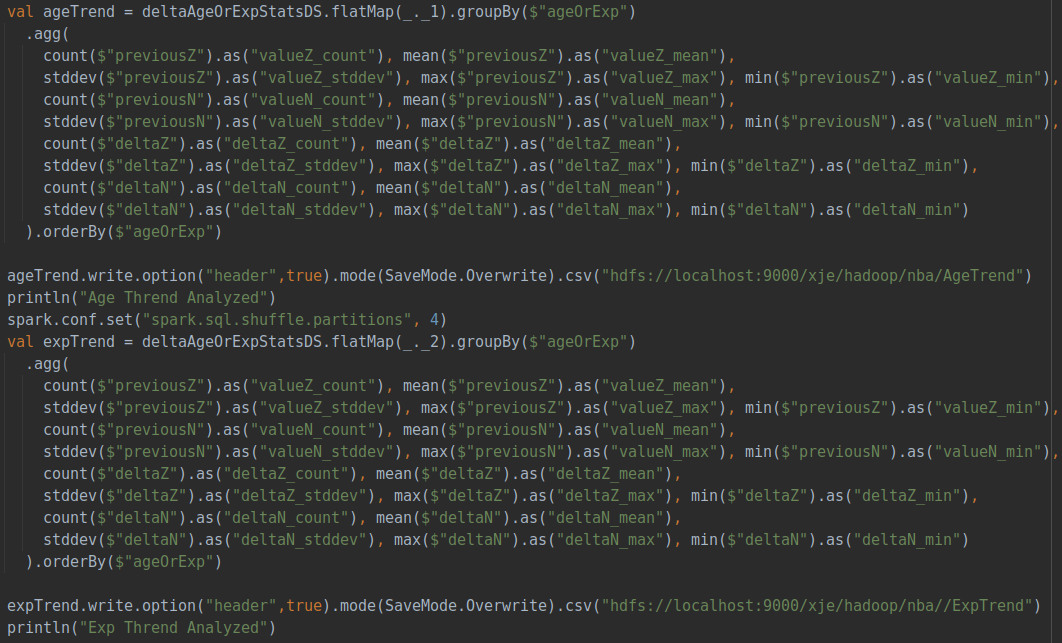
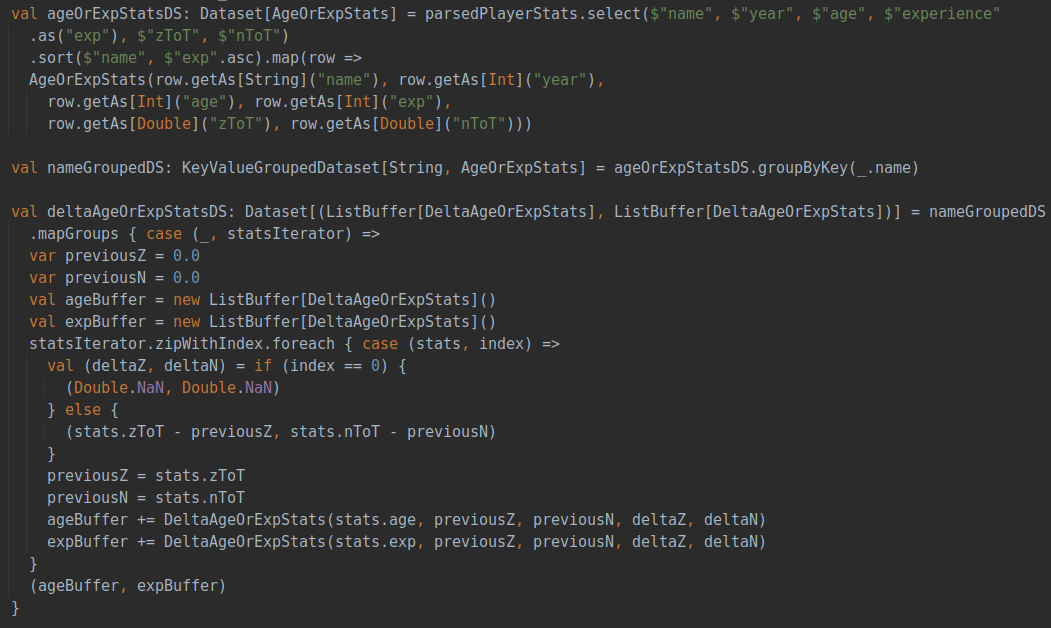
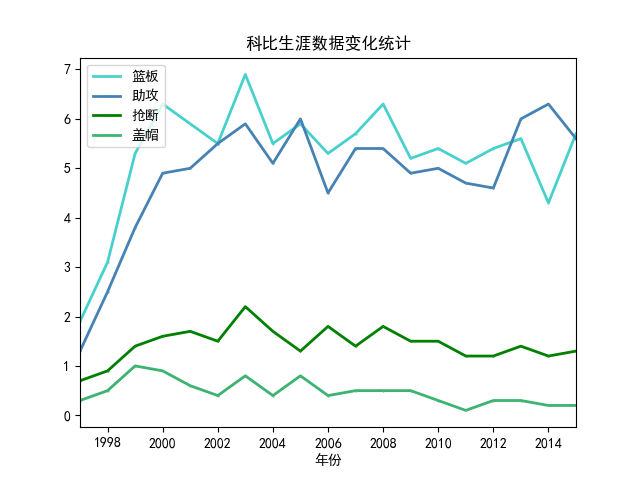
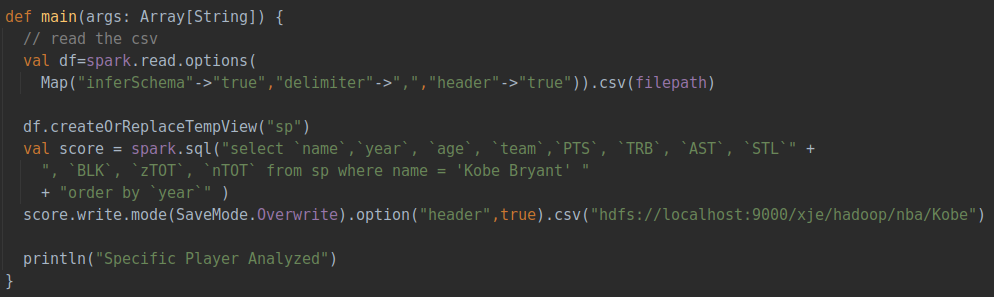
(5)具体球员数据及身价变化分析
这部分分析任意球员在不同赛季的数据变化情况,然后根据计算出来的球员值zScore,分析该球员的数据随着赛季的进行变化情况。同样,先使用Spark读取预处理好的CSV文件,然后使用SQL select方法从指定球员的数据中筛选出需要的字段,具体代码如下:
五、结果可视化(1)可视化工具
使用Python语言对结果数据进行可视化,具体使用的版本和库如下:
Python 3.10.4
熊猫
Matplotlib
(2)主要数据排序可视化结果
(3)三分球数据变化可视化结果
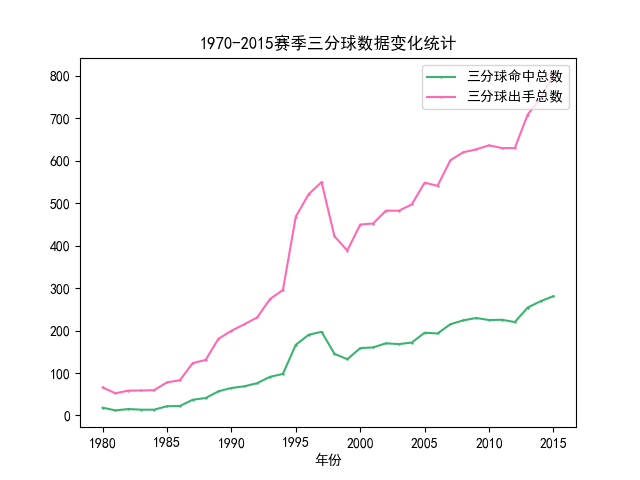
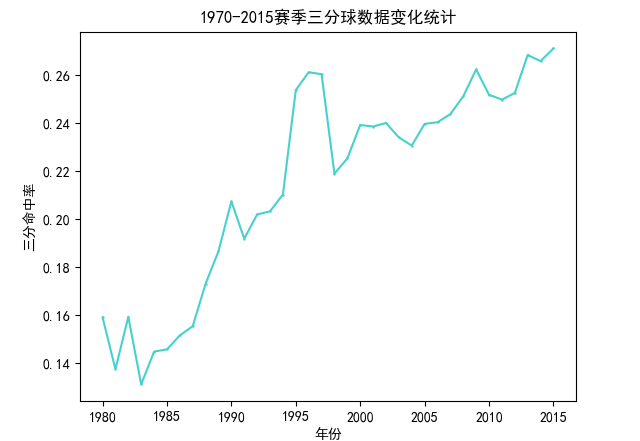
(4)球员所效力球队数量的可视化
(5)球员价值随年龄变化的可视化
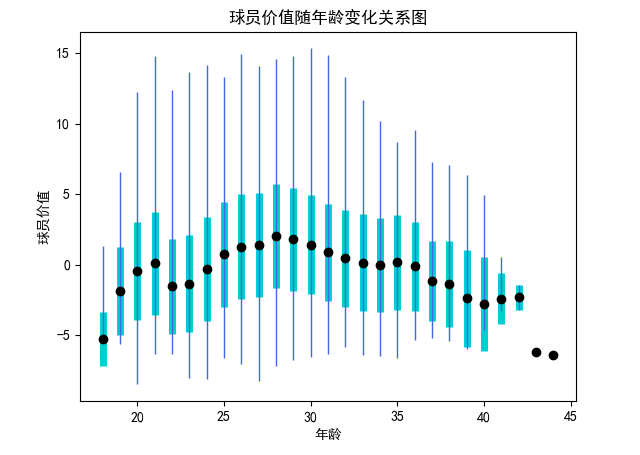
(6)球员价值随年龄变化的可视化
(7)具体球员数据变化分析可视化结果